|
|
 发表于 2019-4-27 22:50:58
|
显示全部楼层
发表于 2019-4-27 22:50:58
|
显示全部楼层
awk is one of the best tools, if not the best, to work with tabular data. 6 x/ k+ Z# g: t) ]& s4 f
on the other hand, powerful it is, regular expression is overly used in the wrong places. # X$ Z, A$ w, q7 h
4 w0 m* ~% d0 L
To solve your problem with awk,* u( F: { [6 b3 H6 @
awk '{for(i=3; i<=NF; i++) if($i==$2) $i = "" } { print }' 2nd-col.txt > 2nd-cleaned.txt
% q# x$ c& W' D9 F. V5 s
9 F& U: H. H) c5 q2 Ksuppose 2nd-col.txt is your original file and 2nd-cleaned.txt is your cleaned file.0 q. n- N: e$ |* |$ v% G% a7 n
I've uploaded a screenshot, but I'm not sure whether it shows correctly.
, B. q0 Y8 f) p, [' d& ]# G9 F9 s6 M" z5 I7 s. ~; _2 q
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?免费注册

x
|




 楼主
楼主
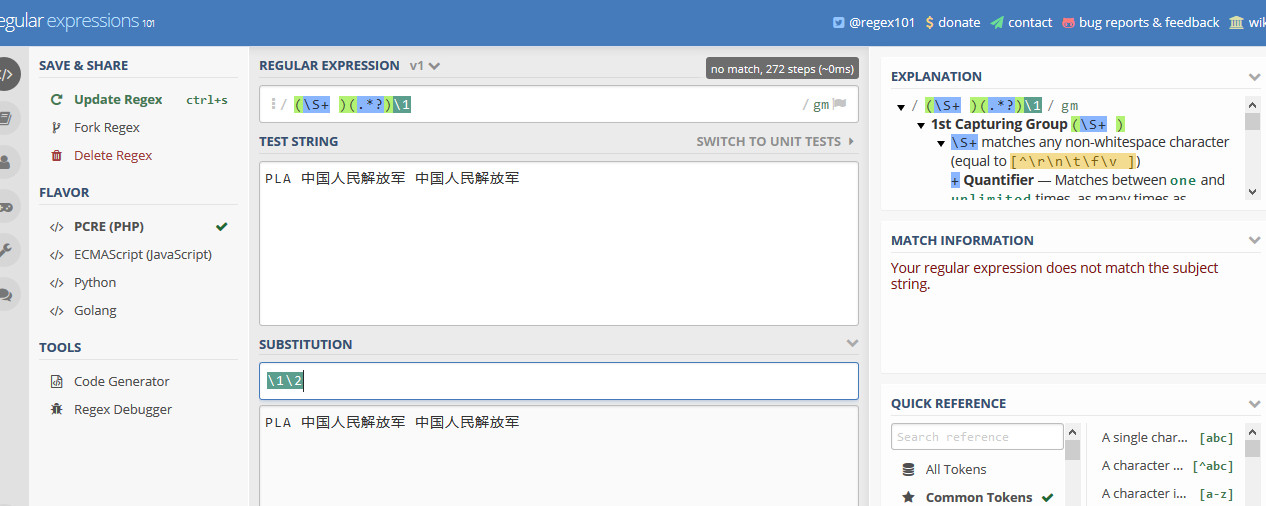 ! [8 K) T8 y' ~1 E5 e* _
! [8 K) T8 y' ~1 E5 e* _
