只需一步,快速开始
该用户从未签到
您需要 登录 才可以下载或查看,没有账号?免费注册
查看全部评分
kyletruman
举报
yingyuxx 发表于 2014-4-13 19:02 # y& V \+ A, n5 {0 e* n8 q P& ~楼主,能用teleport pro抓取网页吗?
Oeasy 发表于 2014-4-13 20:14 2 x0 j# k' X% x* Y' Y2 B子曾经曰过:“此事非难,唯欲行之云耳。”$ ^4 ~9 @ X! B1 I5 F2 f 祝贺楼主。
签到天数: 7 天
[LV.3]偶尔看看II
签到天数: 1 天
[LV.1]初来乍到
tsiank 发表于 2014-4-14 13:22 " @9 u9 p1 ^' s$ m' w2 p/ u w" }! y, d 你好,可不可以帮我提取一下这个网站http://www.eastling.org/OC/oldage.aspx的数据?
tsiank 发表于 2014-4-14 13:22 # l( p3 D- O4 r, R, `你好,可不可以帮我提取一下这个网站http://www.eastling.org/OC/oldage.aspx的数据?
Oeasy 发表于 2014-4-14 18:48 & F2 Z, w7 Q" w$ Q$ Z 这网站很高大上啊,抓取不易,不如直接和站长联系,看是否能够获取。 - t2 \: D J6 H" @" B5 J, u0 \/ K" m7 {5 D6 v) u. l 另蓝海兄可以看看这个
签到天数: 5 天
[LV.2]偶尔看看I
perhapz 发表于 2014-4-16 19:57 $ y/ D! R0 o3 E+ f7 v sublime?
签到天数: 413 天
[LV.9]以坛为家II
签到天数: 384 天
签到天数: 16 天
[LV.4]偶尔看看III
签到天数: 279 天
[LV.8]以坛为家I
本版积分规则 发表回复 回帖后跳转到最后一页
小黑屋|手机版|Archiver|PDAWIKI |网站地图
GMT+8, 2025-5-17 14:35 , Processed in 0.027466 second(s), 30 queries .
Powered by Discuz! X3.4
© 2001-2023 Discuz! Team.

 [复制链接]
[复制链接]


 发表于 2014-4-13 18:45:23
发表于 2014-4-13 18:45:23
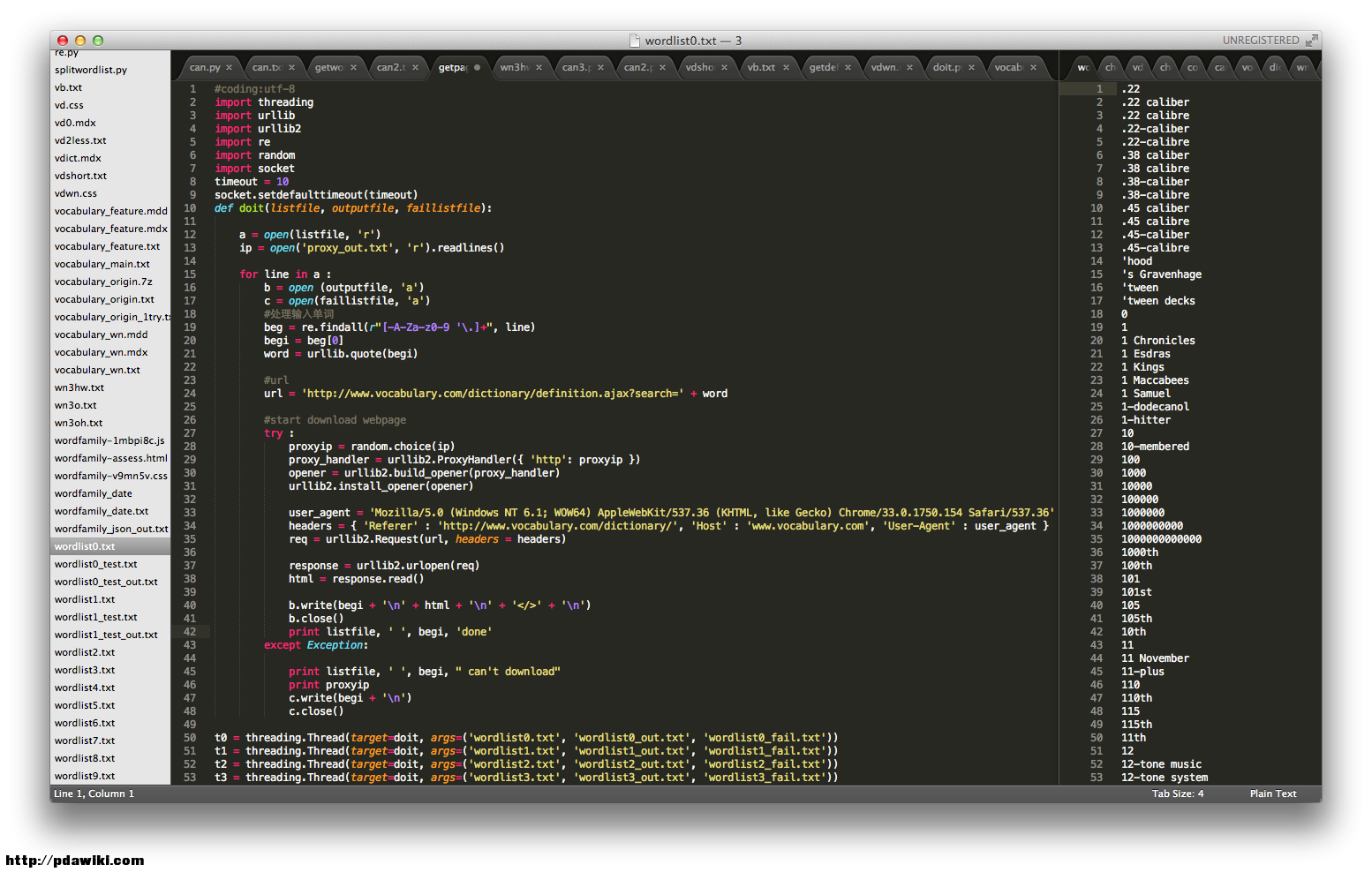 % C6 j4 M+ T. Y* |, u. s
% C6 j4 M+ T. Y* |, u. s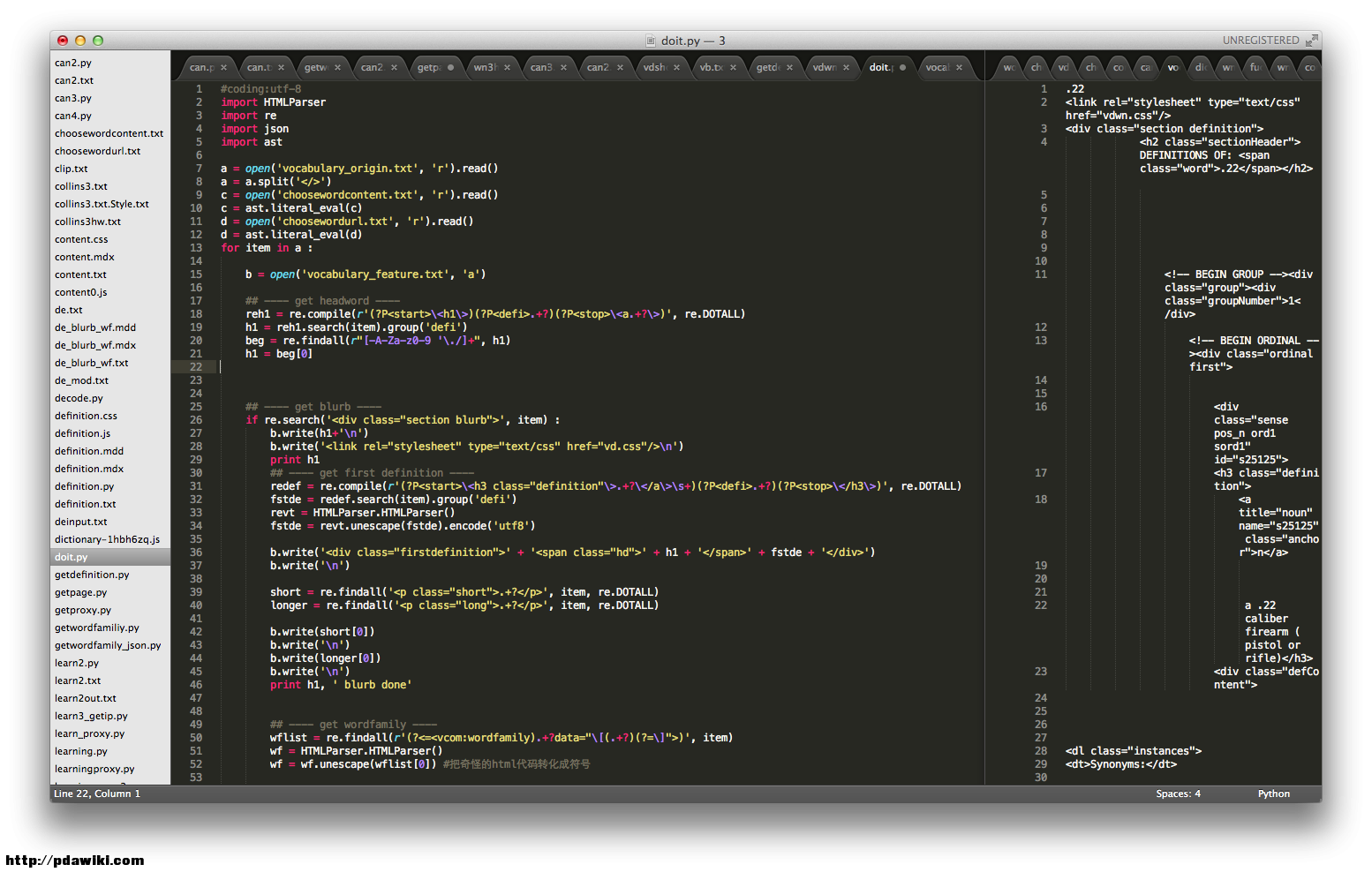

 楼主
楼主





