|
|
 发表于 2015-11-19 22:33:07
|
显示全部楼层
发表于 2015-11-19 22:33:07
|
显示全部楼层
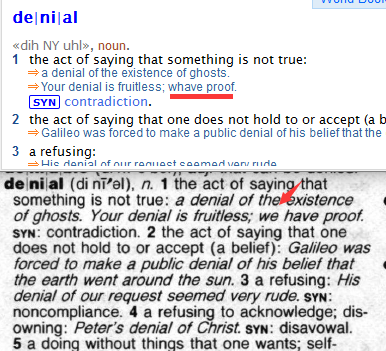
可惜没有词头, 因为PDF的词头OCR效果不是很好.
+ o' |/ b0 z9 z+ }' R8 ?5 e3 kairframe 的OCR => ai r fram e
& J) H" x% }. I1 S1 U( p8 o- vbobcat 的OCR => bo b ca t p A' K- m& W, L# _
所以我才想用从” See picture under”往前35个文本来当查找的依据.
- Q6 B2 t5 Y( ^
M0 D% N/ b) L9 v5 R+ A另外, 我也还没有完成PDF转TXT的断行整理! T, k7 z8 _9 q" z |$ Q M5 c
光是想将行尾的 “空白\n” 删除掉 \n, PC就得花不少时间..我就先中断了." [5 X& b8 Y- t+ z7 T: k; }
但若不先处理TXT的断行, 也会抓不到数据..7 o! K8 W. {8 [
|
|



 楼主
楼主 % G0 j; c. c6 y
% G0 j; c. c6 y
 / n6 D7 P. q6 d) _) @
/ n6 D7 P. q6 d) _) @